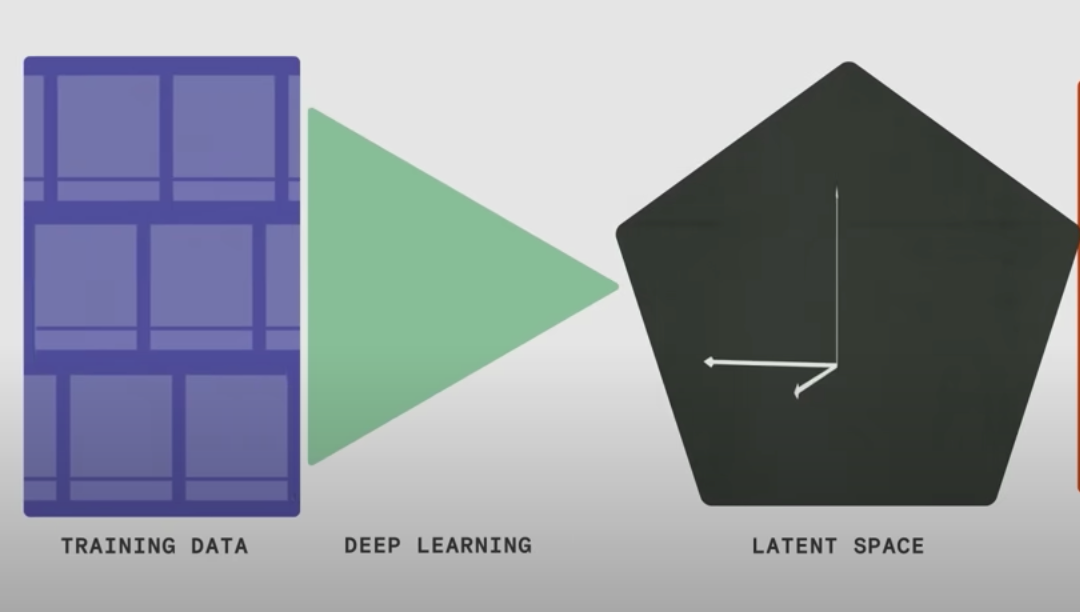
VOX- The text-to-image revolution, explained — cap from YouTube
VOX- The text-to-image revolution, explained — cap from YouTube
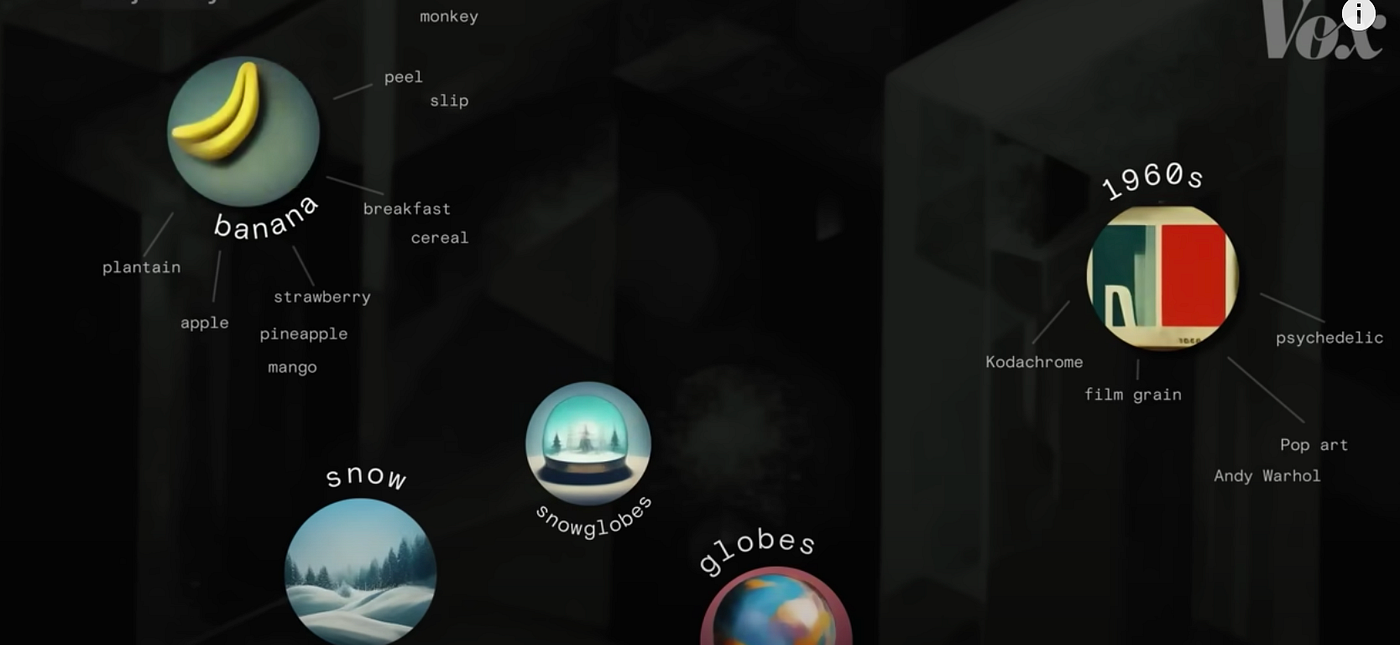
VOX- The text-to-image revolution, explained — cap from YouTube

image from Nvidia Diffusion models explained
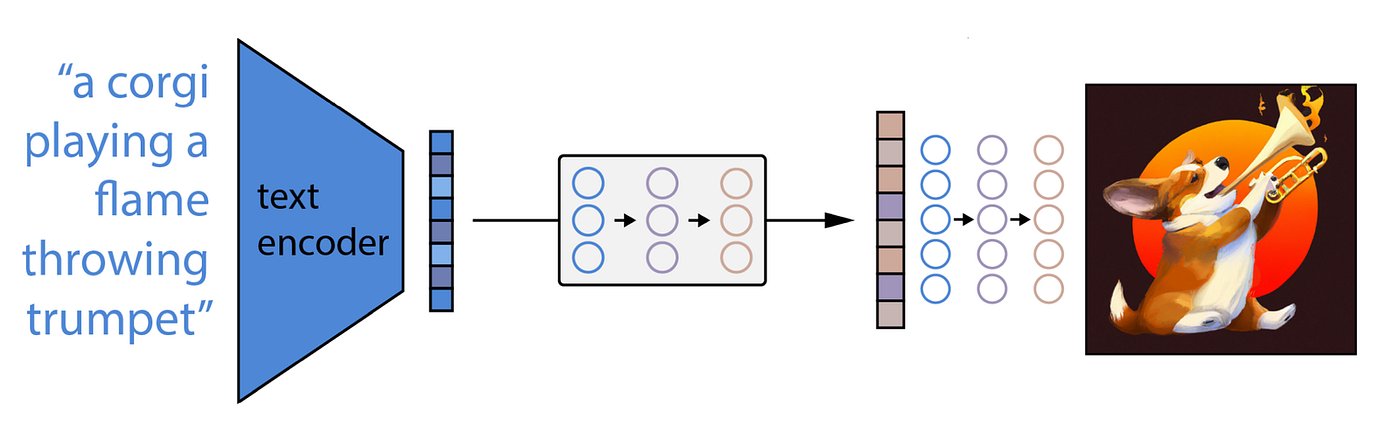
High-level overview of the DALL-E 2 image-generation process, modified by AssemblyAI

Made by Author on Midjourney

made by author on Midjourney